 蓝时代
蓝时代
尽管川普的走马上任更多与“逆全球化”绑定在一起,但考虑到人类历史“螺旋状”上升的演化轨迹,在技术进步和文化扩散的双重推动下,这个世界总体趋向互通互联的趋势似乎不可违——尤其当全球化与网络相遇的一瞬,不同国家之间平等便捷获取信息,低成本地有效沟通即成一种必然。从这个意义上,全球化的最大敌人之一也许是各国千百年来夯实的语言壁垒。
作为一门交叉学科,机器翻译涉及到认知科学,计算机,信息论,语言学等多学科,其理论路径同样经历了螺旋状上升:从最久远的“翻译备忘录”到后期基于规则,基于实例的机器翻译,再到被视为机器翻译重要转捩点的统计翻译模型(SMT)——后者是科学家初次察觉到通过大数据消弭信息不确定性是攻克“智能”的好办法。
而最近两年,机器翻译正在拥抱另一个更重要的技术转折点——基于神经网络的机器翻译(NMT:Neural Machine Translation)。
机器翻译的技术路径
感同身受的是,无论是普通用户还是资深译员,无论使用WEB还是APP,都明显察觉到近些年来的翻译质量有着迅猛的提升。
问题是:为何变化如此明显?不妨从技术路径上拆解来看。
直觉便知,当人类试图让机器翻译语言时,自然要对文字进行解构,就像同心圆的关系,文章由段落构成,段落由句子构成,句子由短语和字构成,而遵循从易到难,机器翻译的理论路径也是从后向前:从最初的逐字翻译到基于短语的翻译——如今,依靠于神经网络,基于句子的翻译成为可能。
于是,按照翻译单元的不同,大体而言,目前机器翻译有两种类型:其一是上文提及的统计翻译模型(SMT),如你所知,互联网的广泛普及为统计翻译提供了丰富的训练养料,而千禧年左右兴起的基于短语的SMT更是让机器翻译质量大为提高,也在很长一段时间占据机器翻译的主流,但以短语作为翻译单元的弊端即是,当面对整句层面的翻译时显得非常生硬。
另一种类型当然是基于神经网络的机器翻译(NMT),其翻译路径是所谓端到端(end-to-end),将源语句整体编码为一个向量,再通过解码器对其进行解码,理论上仅需给定源语言句子,即可通过神经网络输出目标语言译文。这里不妨举个例子,若你在百度翻译中输入“萝卜青菜各有所爱”,它可以轻松输出“Every man has his hobbyhorse”的正确译文,而非诸如“Turnip greens his taste”的荒诞结果。也正因如此,短短两年,NMT就在多个公开测试集上超越了作为前辈的SMT系统。
而若要比较的话,整体而言,在数据训练比较充分的时候,NMT无疑要优于SMT;在短句或数据量相对较小之时,SMT在处理固定搭配和习惯表达上具有优势。所以两种方式谈不上殊途同归,只是在不同场景中分类而用——要知道,用户的翻译场景颇为多变,这要求一个优秀的翻译系统要成为集大成者。如今百度的翻译系统就包含SMT,NMT,甚至更传统的EBMT(基于实例的机器翻译)。
当然,倘若我们谈论的是未来,几乎可以肯定,神经网络技术本身的向前奔进,会让NMT日趋成为主流(事实上,在百度中英日韩等多个系统中,它已是主流)——在今年8月的国际计算语言学年会上(ACL),移动端离线NMT被列为未来重要研究方向,即是为机器翻译的未来画了一个几乎确定性的脚注。
机器翻译的跑马圈地
自二十世纪三十年代初法国科学家阿尔楚尼提出用机器进行翻译的想法至今,哪怕对人工智能的定义已几经翻折,机器翻译都被长期视为人工智能的“终极目标”之一。巨大的期许往往意味着目标艰难,但这仍然无法阻挡这块大蛋糕对全球顶尖科技大佬的吸引力。
而作为翻译技术发展的初级阶段,如果在这个时候硬要拼个排名或者高下,其实并没有太大意义,而科技界的竞争也无非就是微软、百度、谷歌这三家而已,孰轻孰重一看便知。只不过,从“百度更懂中国”的大思路能够看出,百度在中国乃至亚洲市场更具侵略性,和搜索之争同理,虽然谁都打不死谁,但区域优势已成不争事实。
12月21日,从百度机器翻译技术开放日上百度技术委员会联席主席、自然语言处理部技术负责人吴华博士的观点可以看出,百度其实已经成为了翻译技术领域的破茧者,他们早于谷歌一年就正式上线了基于神经网络的翻译系统,同时也打造了全球首个互联网在线NMT系统以及手机端离线NMT系统。据悉,百度翻译每天已有上亿次访问,支持28种语言的互译,开方的API接口也有超过2万家第三方接入。
而就在前几天,微软发布全球首个万能翻译器,微软官方表示它也可以实现多达100人间实时翻译交谈,并支持9种语言的语音输入。而谷歌全球化带来的影响无疑的巨大的,在收购科技公司的同时也在大力发展区域化优势,如谷歌2014年收购的Word Lens也在积极开展机器翻译的工作,这李彦宏所说的话是一样的道理:用人工智能打破一切边界。
其实,百度的现状其实并不令人意外,考虑到中国经济在全球化中的地位,在将更多人卷入全球化的社会协作网络过程中,中国对翻译行为的仰仗无疑更迫切。而更为现实的是:在全球数万亿网页中,80%为非中文网页;去年中国出境游人数超过1.2亿,前20个旅游目的地国家和地区中共使用了12种语言,尤其是中英语——这个世界上使用人数最多和使用最广泛的两种语言之间的翻译,在很多人眼中是纯粹的刚需。
机器翻译的未来
很简单,翻译技术最终是要服务大众,否则就是镜中月、水中花。
重要的是,技术也逐渐还原到更具体的实用场景,百度翻译APP就通过结合OCR技术和语音技术,为用户满足各种碎片化的翻译需求,举几个例子:当你在国外游览时,只需将手机屏幕对准外文介绍,OCR翻译即可呈现翻译结果;面对天书一般的外文菜单,百度翻译可以迅捷地将菜单翻译结果显示在手机上,从此不必再在点餐时听天由命;在国外买买买时,它也能让你快速读懂说明书;另外,当遇到不认识的实物,实物翻译可以用中英双语告知其名,同时伴随着准确的发音;而结合语音技术的会话翻译,能帮助用户与外国人无障碍交流——我甚至还看到过这样的新闻:靖江市民警在语言不通的情况下,用百度翻译成功救助4名俄罗斯籍船员……
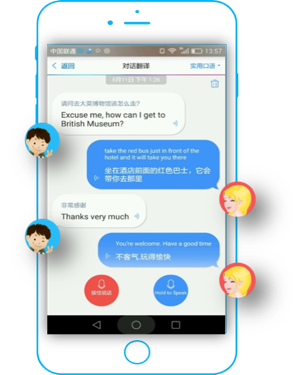
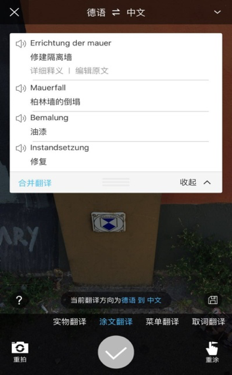
技术的福祉正在惠及每一位担心语言关的人,而另一端,一部分人对技术的忧虑也在所难免。“未来若干年,我们很容易想象语言障碍会完全被打破,现在做同声翻译的人可能将来就没有工作了。”上个月的乌镇互联网大会,李彦宏为人们勾勒了未来的场景。
机器虽然突破了固有翻译原则的局限,但必须承认的是,机器翻译和真正意义上的“语言学”还关系不大,距离文人向往的“信雅达”目标还很遥远,这也意味着,机器翻译任重道远,人工翻译可稍安勿躁。
究其原因,在基于端到端的翻译手法中,神经网络无法理解自己翻译出的句子,无法对译文给出一个合理解释——这正是它与专业人工翻译最本质的差别。譬如,遵循上文提及的从后向前(从易到难)的理论路径,让机器理解基于“段落”甚至“篇章”的翻译自然再好不过,这要求机器在上下文理解和连贯性上飞跃一大步。
那么问题是:它会实现么?作为技术乐观主义者,我个人答案当然是会,一切或许只是时间问题。
在昔日古老的岁月,人类诞生语言的原始目的,一方面是增进本族人的内部沟通,另一方面是制造与外族的天然隔阂。而若你相信技术的发展内嵌在全球化的伟大浪潮中,通过技术终结千万年来人类语言互不相通的历史就值得期许。毕竟,让人们听懂彼此,这是一个太过古老的夙愿。
李北辰/文
声明:本文内容和图片仅代表作者观点,不代表蓝时代网立场。蓝时代 » 神经网络革命,能否让机器翻译打破人类语言壁垒?